ESMM
不同的目标由于业务逻辑,有显式的依赖关系,例如曝光→点击→转化。用户必然是在商品曝光界面中,先点击了商品,才有可能购买转化。阿里提出了 ESMM (Entire Space Multi-Task Model) 网络,显式建模具有依赖关系的任务联合训练。该模型虽然为多任务学习模型,但本质上是以 CVR 为主任务,引入 CTR 和 CTCVR 作为辅助任务,解决 CVR 预估的挑战。
背景与动机
传统的 CVR 预估问题存在着两个主要的问题:样本选择偏差和稀疏数据。下图的白色背景是曝光数据,灰色背景是点击行为数据,黑色背景是购买行为数据。传统 CVR 预估使用的训练样本仅为灰色和黑色的数据。
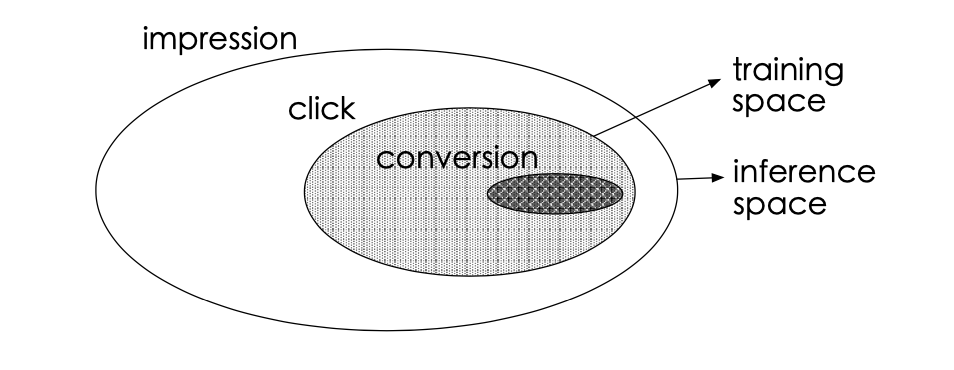
这会导致两个问题:
- 样本选择偏差(sample selection bias,SSB):如图所示,CVR 模型的正负样本集合 ={点击后未转化的负样本 + 点击后转化的正样本},但是线上预测的时候是样本一旦曝光,就需要预测出 CVR 和 CTR 以排序,样本集合 ={曝光的样本}。构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中训练数据和测试数据独立同分布的假设。
- 训练数据稀疏(data sparsity,DS):点击样本只占整个曝光样本的很小一部分,而转化样本又只占点击样本的很小一部分。如果只用点击后的数据训练 CVR 模型,可用的样本将极其稀疏。
解决方案
阿里妈妈团队提出 ESMM,借鉴多任务学习的思路,引入两个辅助任务 CTR、CTCVR (已点击然后转化),同时消除以上两个问题。
三个预测任务如下:
- pCTR:p(click=1 | impression);
- pCVR: p(conversion=1 | click=1,impression);
- pCTCVR: p(conversion=1, click=1 | impression) = p(click=1 | impression) * p(conversion=1 | click=1, impression);
注意:其中只有 CTR 和 CVR 的 label 都同时为 1 时,CTCVR 的 label 才是正样本 1。如果出现 CTR=0,CVR=1 的样本,则为不合法样本,需删除。 pCTCVR 是指,当用户已经点击的前提下,用户会购买的概率;pCVR 是指如果用户点击了,会购买的概率。
三个任务之间的关系为:
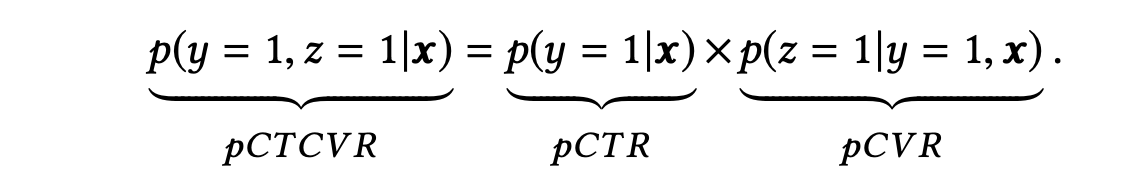
其中 x 表示曝光,y 表示点击,z 表示转化。针对这三个任务,设计了如图所示的模型结构:
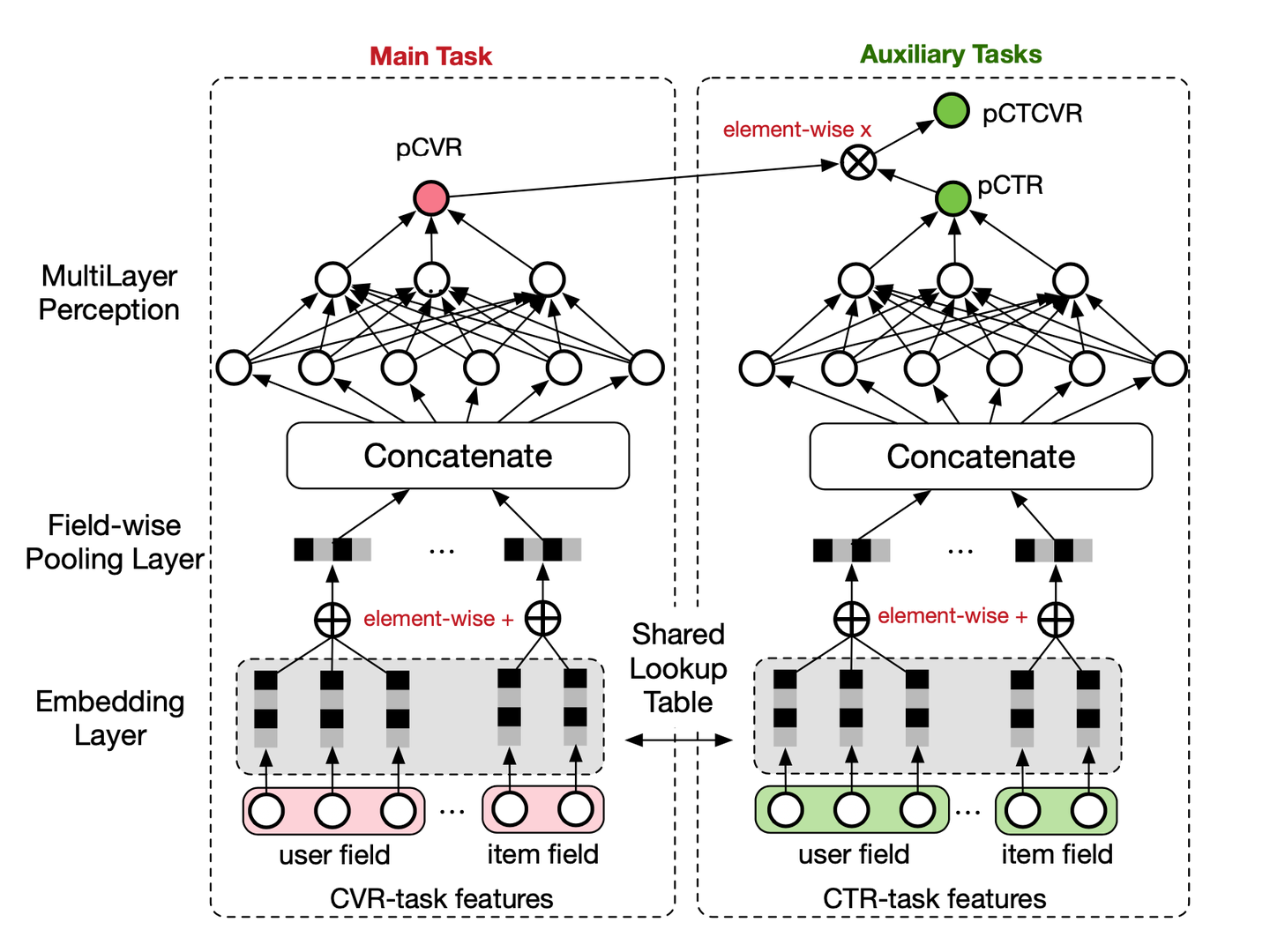
如图,主任务和辅助任务共享特征,不同任务输出层使用不同的网络,将 cvr 的预测值 * ctr 的预测值作为 ctcvr 任务的预测值,利用 ctcvr 和 ctr 的 label 构造损失函数:
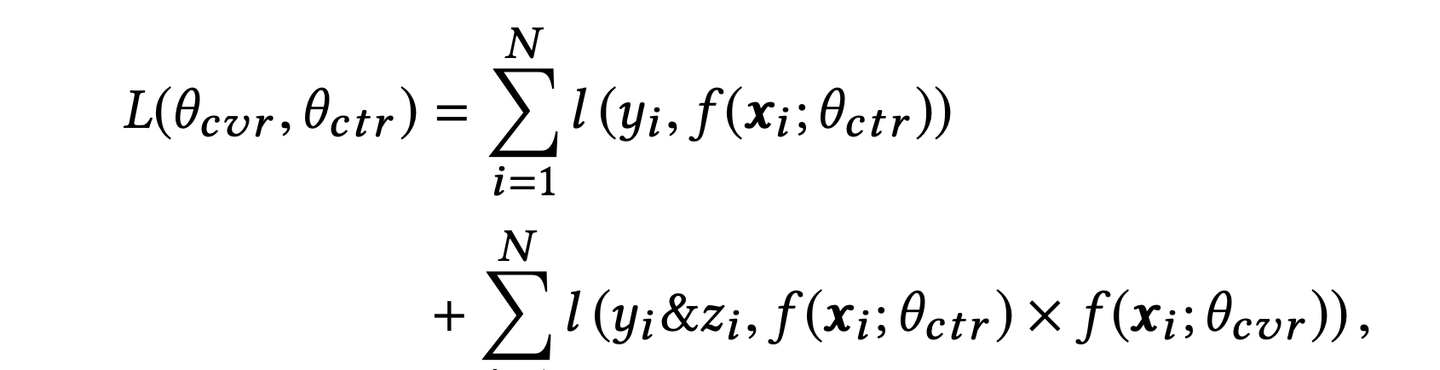
该架构具有两大特点,分别给出上述两个问题的解决方案:
帮助 CVR 模型在完整样本空间建模(即曝光空间 X)。
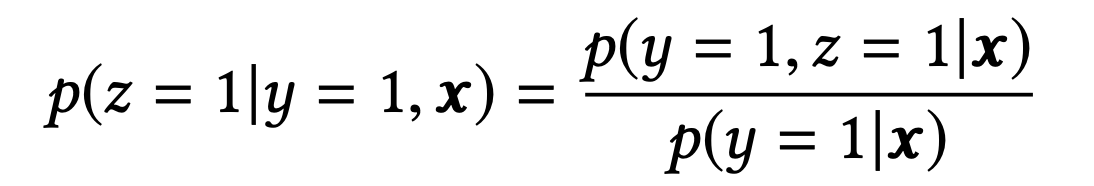
从公式中可以看出,pCVR 可以由 pCTR 和 pCTCVR 推导出。从原理上来说,相当于分别单独训练两个模型拟合出 pCTR 和 pCTCVR,再通过 pCTCVR 除以 pCTR 得到最终的拟合目标 pCVR 。在训练过程中,模型只需要预测 pCTCVR 和 pCTR,利用两种相加组成的联合 loss 更新参数。pCVR 只是一个中间变量。而 pCTCVR 和 pCTR 的数据是在完整样本空间中提取的,从而相当于 pCVR 也是在整个曝光样本空间中建模。
- 提供特征表达的迁移学习(embedding 层共享)。CVR 和 CTR 任务的两个子网络共享 embedding 层,网络的 embedding 层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数占了整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。由于 CTR 任务的训练样本量要大大超过 CVR 任务的训练样本量,ESMM 模型中特征表示共享的机制能够使得 CVR 子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题。
模型训练完成后,可以同时预测 cvr、ctr、ctcvr 三个指标,线上根据实际需求进行融合或者只采用此模型得到的 cvr 预估值。
总结与拓展
可以思考以下几个问题
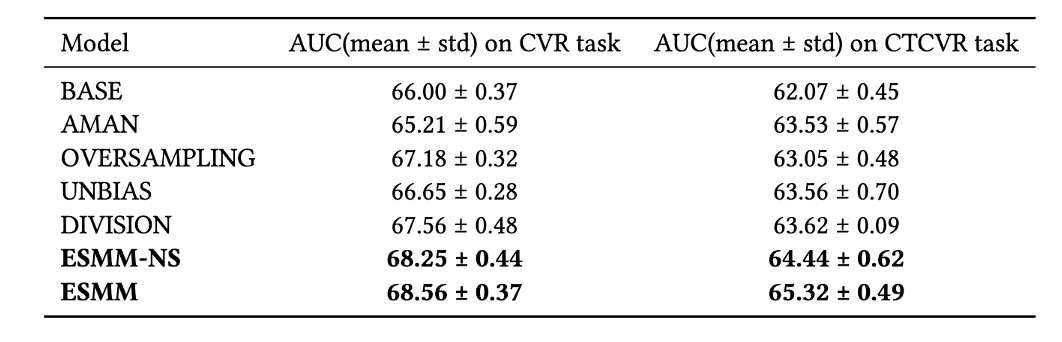
能不能将乘法换成除法? 即分别训练 CTR 和 CTCVR 模型,两者相除得到 pCVR。论文提供了消融实验的结果,表中的 DIVISION 模型,比起 BASE 模型直接建模 CTCVRR 和 CVR,有显著提高,但低于 ESMM。原因是 pCTR 通常很小,除以一个很小的浮点数容易引起数值不稳定问题。
网络结构优化,Tower 模型更换?两个塔不一致? 原论文中的子任务独立的 Tower 网络是纯 MLP 模型,事实上业界在使用过程中一般会采用更为先进的模型(例如 DeepFM、DIN 等),两个塔也完全可以根据自身特点设置不一样的模型。这也是 ESMM 框架的优势,子网络可以任意替换,非常容易与其他学习模型集成。
比 loss 直接相加更好的方式? 原论文是将两个 loss 直接相加,还可以引入动态加权的学习机制。
更长的序列依赖建模? 有些业务的依赖关系不止有曝光 - 点击 - 转化三层,后续的改进模型提出了更深层次的任务依赖关系建模。
阿里的 ESMM2: 在点击到购买之前,用户还有可能产生加入购物车(Cart)、加入心愿单(Wish)等行为。
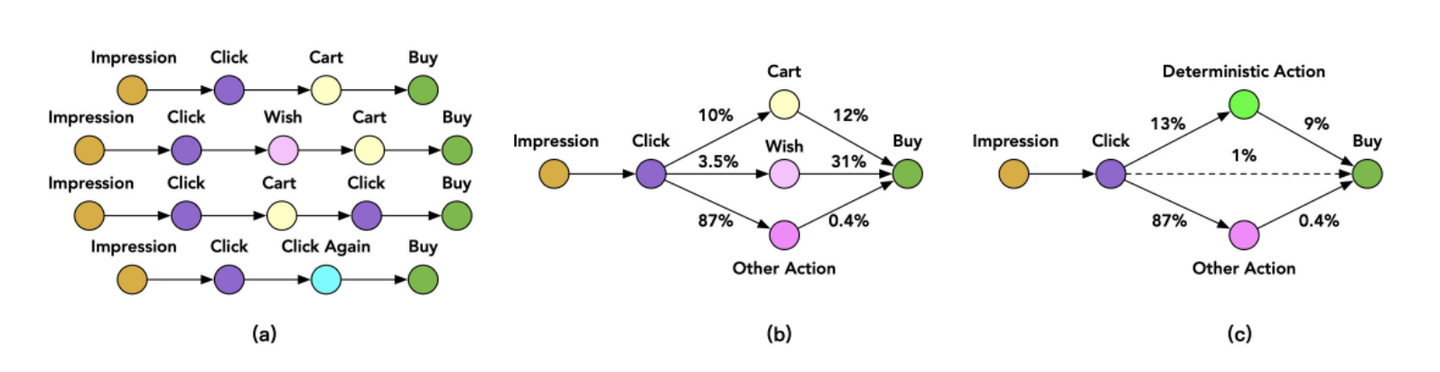
相较于直接学习 click->buy (稀疏度约 2.6%),可以通过 Action 路径将目标分解,以 Cart 为例:click->cart (稀疏 度为 10%),cart->buy (稀疏度为 12%),通过分解路径,建立多任务学习模型来分步求解 CVR 模型,缓解稀疏问题,该模型同样也引入了特征共享机制。
美团的 AITM:信用卡业务中,用户转化通常是一个曝光 -> 点击 -> 申请 -> 核卡 -> 激活的过程,具有 5 层的链路。
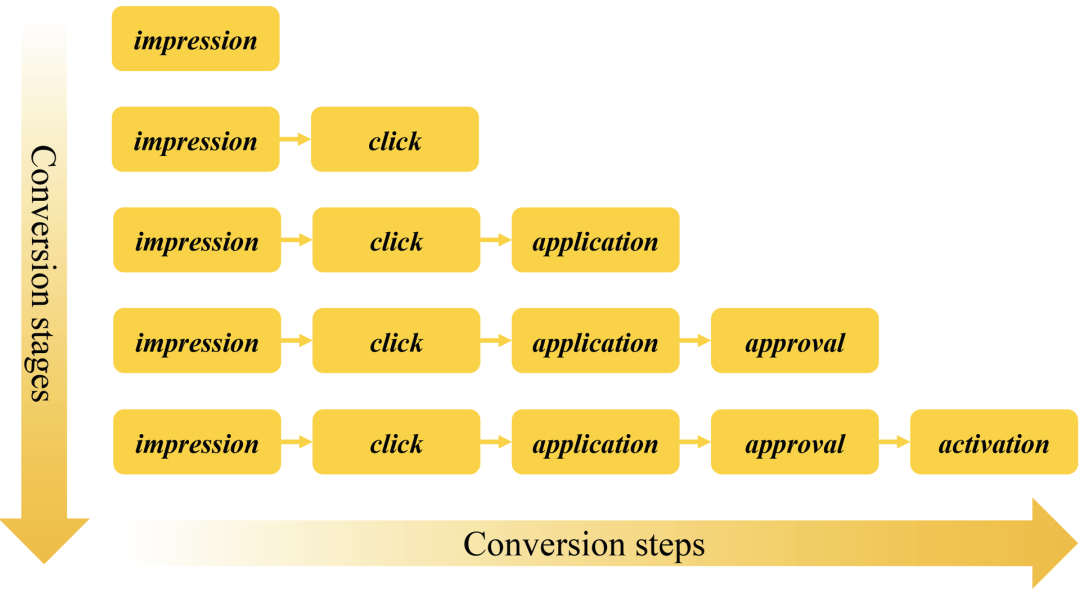
美团提出了一种自适应信息迁移多任务(**Adaptive Information Transfer Multi-task,AITM**)框架,该框架通过自适应信息迁移(AIT)模块对用户多步转化之间的序列依赖进行建模。AIT模块可以自适应地学习在不同的转化阶段需要迁移什么和迁移多少信息。
总结:
ESMM 首创了利用用户行为序列数据在完整样本空间建模,并提出利用学习 CTR 和 CTCVR 的辅助任务,迂回学习 CVR,避免了传统 CVR 模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。
代码实践
与 Shared-Bottom 同样的共享底层机制,之后两个独立的 Tower 网络,分别输出 CVR 和 CTR,计算 loss 时只利用 CTR 与 CTCVR 的 loss。CVR Tower 完成自身网络更新,CTR Tower 同时完成自身网络和 Embedding 参数更新。在评估模型性能时,重点是评估主任务 CVR 的 auc。
def ESSM(dnn_feature_columns, task_type='binary', task_names=['ctr', 'ctcvr'],
tower_dnn_units_lists=[[128, 128],[128, 128]], l2_reg_embedding=0.00001, l2_reg_dnn=0,
seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
features = build_input_features(dnn_feature_columns)
inputs_list = list(features.values())
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
ctr_output = DNN(tower_dnn_units_lists[0], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
cvr_output = DNN(tower_dnn_units_lists[1], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
ctr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(ctr_output)
cvr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(cvr_output)
ctr_pred = PredictionLayer(task_type, name=task_names[0])(ctr_logit)
cvr_pred = PredictionLayer(task_type)(cvr_logit)
ctcvr_pred = tf.keras.layers.Multiply(name=task_names[1])([ctr_pred, cvr_pred])#CTCVR = CTR * CVR
model = tf.keras.models.Model(inputs=inputs_list, outputs=[ctr_pred, cvr_pred, ctcvr_pred])
return model测试数据集:
adult:census+income
将里面两个特征转为 label,完成两个任务的预测:
- 任务 1 预测该用户收入是否大于 50K,
- 任务 2 预测该用户的婚姻是否未婚。
以上两个任务均为二分类任务,使用交叉熵作为损失函数。在 ESMM 框架下,我们把任务 1 作为 CTR 任务,任务 2 作为 CVR 任务,两者 label 相乘得到 CTCVR 任务的标签。
除 ESSM 之外,之后的 MMOE、PLE 模型都使用本数据集做测试。
注意上述代码,并未实现论文模型图中提到的 field element-wise + 模块。该模块实现较为简单,即分别把用户、商品相关特征的 embedding 求和再拼接,然后输入 Tower 网络。我们使用数据不具有该属性,暂未区分。
参考资料:
https://www.zhihu.com/question/475787809
https://zhuanlan.zhihu.com/p/37562283
美团:https://cloud.tencent.com/developer/article/1868117
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate (SIGIR'2018)