AI 相关技术速览
一次关于 “从何处来,往哪里去” 的讨论是极好的起点。
Author:Oops
零、Intro
在一切开始之前,我们必须搞清楚当我们讨论 AI 的时候,我们到底在谈论什么。
望文生义,人工智能即是人造的、有智慧的东西。这里有一个重要却悬而未决的定义 —— 什么是智能?
按照当下的形势,智能确乎是知识和运用知识的能力无疑了。如此,我们就拥有了不少的人工智能😇,他们的统一特征是能够理解我们给出的文字甚至图片,然后根据要求以文字等形式回复我们。这种能够进行 NLP(自然语言处理)的强力模型,我们称为 LLM(大型语言模型)。当然还有一些模型是多模态的,他们能够处理图像、语言、视频,总体来说我们把这些技术统一称为 Deep Learning(深度学习),它是 Machine Learning(机器学习)的一个子集。人工智能一般指使用了深度学习训练的模型,而机器学习一般被认为是基于统计学的工具,所以深度学习也可以说是统计学和其他技术的结合。
本文将从 DeepSeek 的开源论文开始,对深度学习乃至人工智能的专业知识和应用进行简单的讨论,力求使用通俗的自然语言(中文)解释所有相关概念。
🤔为什么要借论文说事?
LLM 是 AI 行业最热门的部分,这些论文所涉及的领域自然也是比较有需求的,我们可以以此来规划自己的学习。
🥰论文链接会贴在文末,这里将采用分类引用的方式进行分享。
一、我们所做的一切努力,到底是在探寻什么?
既然是漫谈杂叙,我们就先来聊聊哲学😎
任何科学都是基于先验知识来处理纷乱的信息,或将蛛丝马迹推理成一个确定的结论,或根据问题得到一个答案。试想一下,我们对自由落体的小球的 v 随 t 的变化数进行拟合,只要样本够多,我们就能得出统计学规律,这就是训练机器学习模型。接着我们已知
二、构建这座大厦的地基
🤔我们在机器学习中如何表示数据?
主体形式毫无疑问是数字。why?
如前文所述,使用先验知识能够大大增加信息处理的效率,数学无疑是人类最伟大的造物,茫茫多的公式可以用来对数据进行变换和调整。
接下来我们用数字表示一张图片的信息:二维坐标和 RGB 值,
这也是一种二维数组,或者我们称为矩阵,或者还有一种称呼:二维张量。
显而易见的,我们需要一种研究矩阵的科学 —— 线性代数,当然还有矩阵论等。
input -> 模型 -> output,这何尝不是一种函数映射,深度学习模型可以理解成一种高维函数。期末考试的考场上,你有一大章没有预习。你无法直接推导出公式,但是你通过题干算出了其中的几对数据,现在你只能不断调整函数形式和参数来尽可能满足所有数据样本,你通过把 x 当成常数对参数求导来找出斜率,以正确调整参数来使函数值不断逼近。这就是梯度下降。
实际上我们处理的数据是高维的并且我们对模型还有其他要求,例如鲁棒性,这时我们使用 MSE、交叉熵、正则化罚等等统计学手段来高效地告诉模型如何进步。对于简单数据,我们使用灵活性小的统计学模型,对于高维数据,我们提高模型的复杂度。
三、训练一个 LLM
先让 LLM 学会说话
我们先构建一个 Tokenizer ,把原始文本 → 模型可消费的整数序列,把单词映射成整数,这个过程何尝不是一种先验知识的应用,我们告诉模型这些字母拼凑一个独特的整体 —— 单词。这样模型就能输出单词,第一步看起来一点也不难实际上没那么简单。
接下来我们希望 LLM 能够说一段流畅的话,我们需要构建一个 base(基座)模型,它拥有海量的知识。
简单来说,模型将上下文信息处理成一个词表中的概率,输出概率最大的那个词。
2017 年 Google 论文《Attention is All You Need》提出了 Transformer 架构,彻底取代了 RNN 和 CNN,成为当今所有大模型的底层架构。
几十年来,模型关联来自两个任意输入或输出位置的信号所需的作数随着位置之间的距离增加而增加,对于 ConvS2S 呈线性增长,对于 ByteNet 呈对数增长。这使得学习遥远位置之间的依赖关系变得更加困难。 在 Transformer 中,这被减少到恒定数量的操作,尽管代价是由于平均注意力加权位置而降低了有效分辨率,但他们用 Multi-Head Attention 来抵消了这种效果。
现在的大模型架构是 Transformer 的改进版,为了减少阅读压力和围绕主旨,这里只介绍 DeepSeek 的架构特点之一 ——MoE(混合专家)。
这种架构把本来密集的神经网络分成多个 “专家” 子网络 ,每次只激活部分专家,这样在减小算力开销的同时保证模型的能力全面,甚至减少了原本 “外行” 的干扰。DeepSeek-V3-Base 就采用了这个架构的负载均衡版本。
教育你的 LLM
现在他不再阿巴阿巴,而是口吐人言,但这还不够,他必须接受教育,成为一个对社会有用的人。
看起来他必须上学, SFT(监督微调) 通过人工编写 “问题 - 答案” 对,使得大模型能够按照指令等人类期望的方式完成任务。这时候的大模型不会推理,没有灵魂。这与我们的最高目标 —— 实现 AGI(通用人工智能) 相去甚远。
为了实现长链、多步推理,人们使用 RL(强化学习),让 AI 自主寻找解决复杂问题的方式,涌现人们想要的智能。
🤔 什么是强化学习?
🌟强化学习就像赛博训狗
1️⃣ 几个核心角色
| 角色 | 现实例子 | 在 “训练小狗捡球” 中的表现 |
|---|---|---|
| 智能体 (Agent) | 你养的哈士奇🐶 | 小狗的 “大脑”,决定要不要跑去捡球 |
| 环境 (Environment) | 小区草坪 | 球场、草丛、其他干扰物(如小朋友) |
| 动作 (Action) | 跑、跳、叼球 | 小狗可做的选择(冲向球 / 原地不动) |
| 奖励 (Reward) | +1 分(做对) /-1 分(做错) | 叼回球:主人摸头 + 零食!✅ 乱跑不理主人:被教训 ❌ |
2️⃣ 强化学习的关键步骤:拆解 “遛狗训练”
想象你第一次教小狗 “把球捡回来”:
小狗行动:看到飞盘扔出去了,它开始思考:“我是去追?还是躺下晒肚皮?”
尝试选择:小狗冲向飞盘(选了 “追” 这个动作)。
环境反馈:
- ✅ 正面奖励:追到了!主人狂喜投喂肉干 → +10 分!
- ❌ 负面惩罚:跑一半被蝴蝶吸引没捡到 → 主人叹气 -5 分
小狗学习:
“跑出去追飞盘 = 好吃的!被蝴蝶吸引 = 没饭吃? 那我以后尽量少看蝴蝶!”
3️⃣ AI 游戏中最典型例子:超级玛丽!
假设你设计一个 AI 玩《超级玛丽》:
- 🍄 目标:通关救公主
- ⚙️ 机制:
- 每一步可以【左 / 右 / 跳 / 冲】→ 动作 (Action)
- 吃到金币💛= +1 分,踩死蘑菇🍄= +10 分,掉坑 = -100 分 → 奖励 (Reward)
- 马里奥站在哪?前方有坑吗? → 环境状态 (State)
👉 AI 怎么学习?
- 先乱按一通! 掉坑扣 100 分 → “我记住了,不能跳坑!” 吃到金币 + 1 分 → “这个好,继续走!”
- 反复 “挨打” 几百万遍后,终于打通关 → 成为老司机✨
这种混合方法已经比较复杂,但通向 AGI 的路道阻且长。
⚠️ SFT+RL 的问题
需大量标注数据,限制了模型的自主演化潜力。 这些方法在通用性和性能上均未达到与 GPT-o1 系列相媲美的水平。
DeepSeek 团队的 R1 主论文的核心动机是验证一个假设:能否仅通过强化学习(无需监督微调)激励 LLMs 的推理能力?
- 传统方法依赖 SFT 提供初始能力,而作者希望让模型 “从零冷启动” 开始,通过 RL 自主演化出复杂推理行为(如反思、验证、长链思维)。
- 目标是通过大规模 RL 训练,证明模型可自发形成高效的问题解决策略,减少对人工标注数据的依赖。
R1 对现有的强化学习算法进行改进,提出 GRPO 算法。并训练模型将思考过程放在特定的标签(如 <think> 和 </think> )之间。
🤔GRPO 的通俗解释
你在下棋,你根据盘面的状态作出相应的动作,而对手会给出反馈。传统算法是如何量化一步棋的好坏呢?用你下完这步棋之后获胜的概率 减去 下这步棋之前获胜的概率。GRPO 就像,在无限个平行时空里,你面对同一个状态,落子在不同位置,然后找出每种下法之后的相对胜率,相对胜率高的就是神之一手。如此就能避免训练评估下这步棋之前获胜的概率的模型。(实际上是大大简化,因为同时也引入了新开销)
这样训练出来的 R1-zero 有着极强的推理能力和低廉的训练成本。但这还不是我们熟悉的 R1,DeepSeek 团队又做了如下的改进,总的来说,在纯 RL 中加入了少量 SFT 来规范语言和增强可读性。
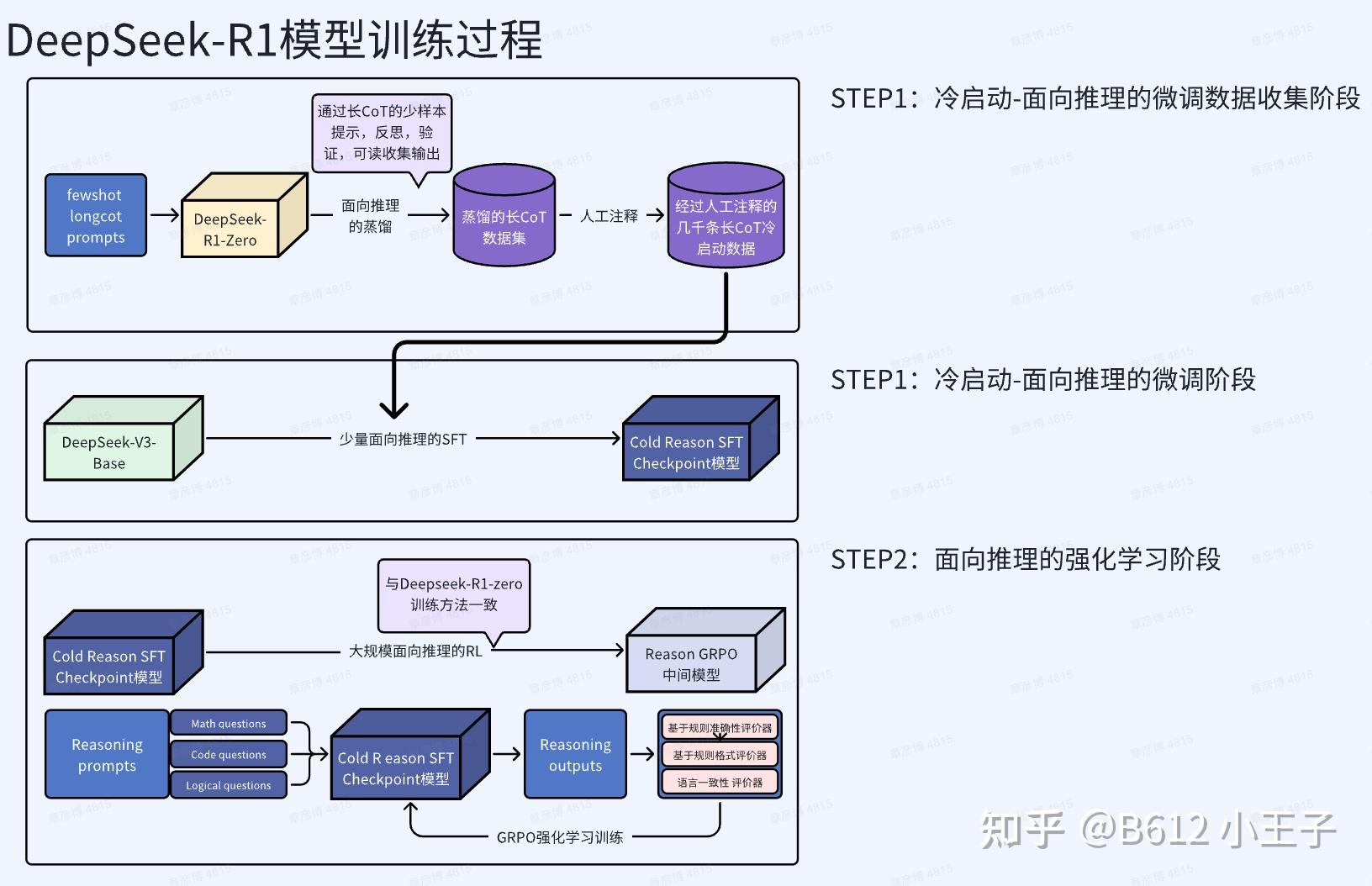
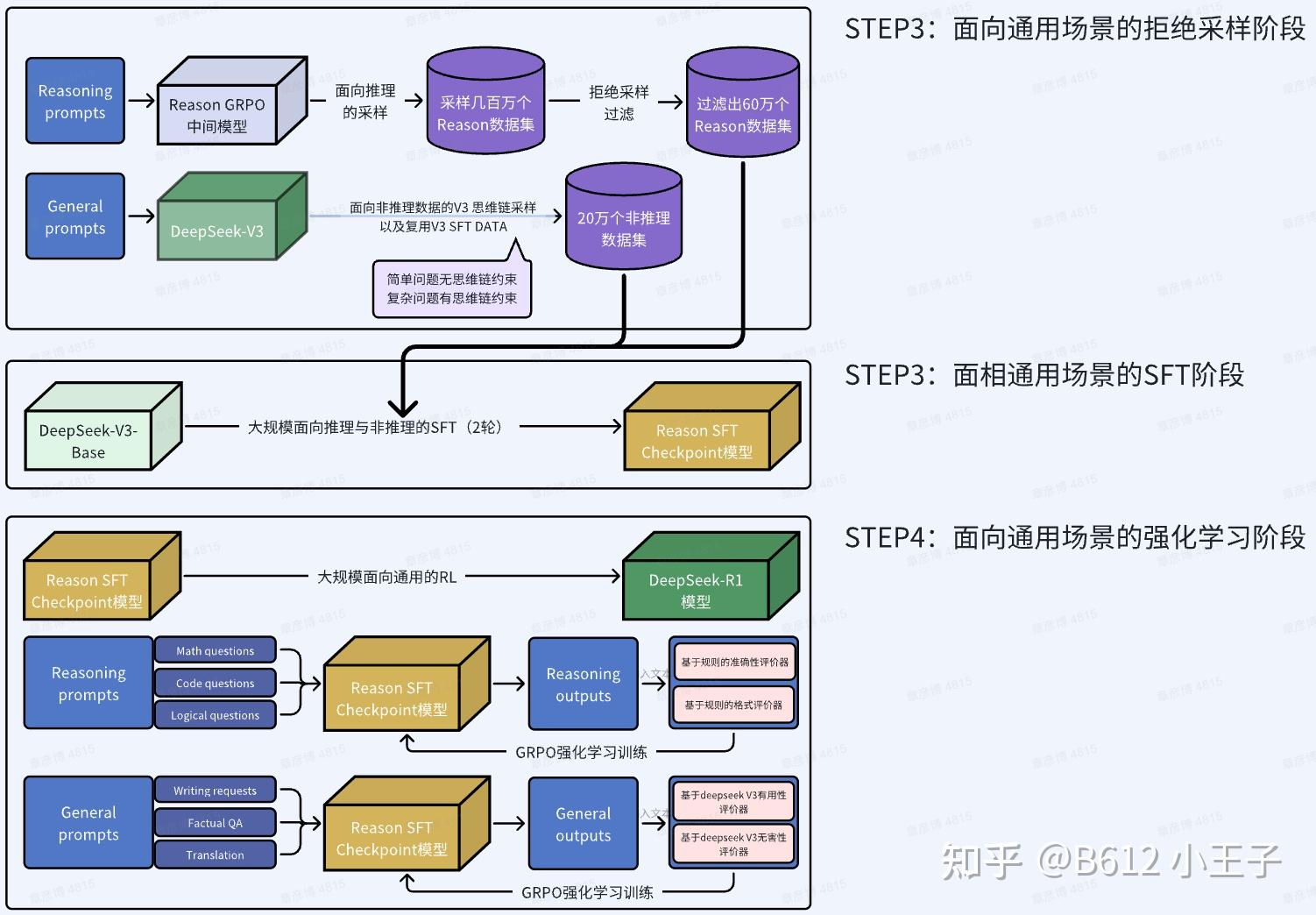
了解详情可以阅读《DeepSeek R1》论文解读
这篇论文还介绍了如何进行小模型蒸馏来继承 R1 的能力。关于在如何最小化精度损失的情况下,减少模型内存和算力开销,可以参考 MIT 6.5940 官网、B 站课程双语字幕视频、以及 Oops 笔记整理中😢
四、抛开数学,如何降本增效
2025 年 7 月 9 日,英伟达(NVIDIA)股价冲破 163.93 美元,市值定格在 4 万亿美元 —— 这一数字超过了英国、法国或德国任一国家的股票总市值。它不仅刷新了苹果 2024 年 12 月创下的 3.92 万亿美元纪录,更标志着全球商业价值的权力交接:微软代表的 “软件霸权” 正式让位于英伟达的 “算力霸权”,宣告人类经济正式进入 “AI 基础设施定义一切” 的时代。
AI 竞赛也是一场显卡军备竞赛,Scaling Low 揭示了模型性能与模型规模存在明确关系,换句话说,更多的算力意味着更强的性能。
DeepSeek 出圈的另一原因就是,挑战了老黄的算力霸权,不只在架构上,也在底层算法上实现了效率提升。
神经网络算法的提出已经是很久远的事了,当时这种方法不被看好,也没有匹配的计算能力让他发挥优势。
🤔什么是神经网络
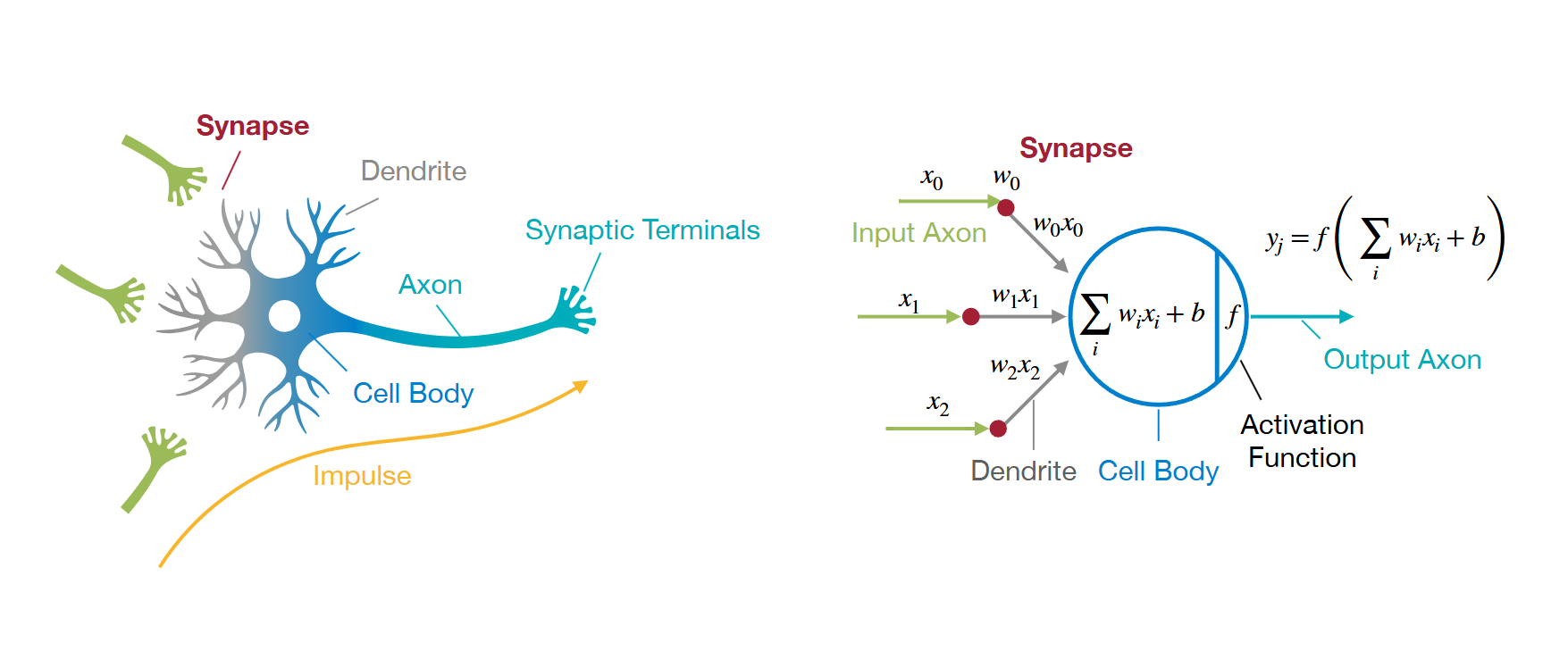
输入轴突 (Input Axon) 就是一般 Machine Learning 所谓的输入特征,所有数学预测都要基于它。
不同输入与不同的权重
这样我们的输出将会是输入向量的线性加权和。
在 2007 年,Nvidia 就推出了基于通用计算的 GPU 软件平台 ——CUDA:Compute Unified Device Architecture。CUDA 定义了一种并行计算的软件接口,它不再专为游戏进行计算,而是一个并行计算的编译、调度和执行的软件平台,这样就可以让许多需要大规模并行计算的科学计算能在 CUDA 上运行,并最终由 GPU 实现加速。
2012 年,AI 三巨头之一的 Hinton 带领他的两个学生 —— 其中之一就是后来 OpenAI 的首席科学家,开发了一种基于 CNN 神经网络的图像识别系统 AlexNet,当时的神经网络计算量非常巨大,程序运行十分缓慢,因此,Hinton 建议他的学生试试 CUDA。结果,通过 CUDA 使用 GPU 加速,Hinton 的三人组轻松击败有百倍、千倍算力和人力的大公司,获得 ImageNet 竞赛冠军,随后谷歌就收购了 Hinton 刚成立的三人公司。
从此,人们就用 CUDA 为 GPU 编程以加速 AI 训练和推理,为了兼容更多、更快的算法和开销更小、使用更便捷的机器学习系统,从事 HPC(高性能计算)的工程师需要编写 CUDA 算子、C++ 程序。
让我们说回到 Tensor(张量),根据之前关于神经网络的介绍可知,最重要的计算任务是 GEMM(矩阵乘法),这是一种可并行度极高的任务。而 GPU 的编程模型正好可以理解成一个三维的方阵,这种 “空间思维编程” 不同于串行的 “时间思维编程”,我们把任务安排给三维空间中的一个个小执行单元,然后它们同时进行计算。
编写 CUDA 代码时我们需要考虑的是如何将任务并行化以及如何结合硬件特性隐藏数据存取的开销等。
并行计算和高性能计算课程 👇
B 站 CoffeeBeforeArch 汉化课程、汉化版 Stanford CS149、知乎 CS149 笔记(不全)
大伙可以直接写一个 SGEMM,看看和 cublas 孰强孰弱。我剑也未尝不利😡
DeepSeek 团队的母公司是幻方量化,一个量化交易企业,他们的业务包括了超高频交易,在高性能编程有着深厚的技术积累,因此他们不满足于 CUDA 编译器的保守编译优化,他们使用定制的 PTX 指令(可以先理解成 CUDA 被编译成 PTX 然后被编译成更底层的表示和机器能够理解的语言)加速了大量显卡之间的通信。
综上所述的部分只是一个个待调用的小算子,我们需要使用 c++ 代码保证其有序运作,这是 AI 编译器的工作。你只需要指定使用哪些算子或者函数,然后它就能自动帮你降低内存和时间的开销。
五、现在我们得到了一个 LLM,然后呢?
来实现一个
AI galgame虚拟伴侣。
作为用户,最方便的使用方法当然是直接使用 AI 公司提供的通用模型。但是,如果我们想拥有一个专属风格或者专门用途的模型,我们需要一点点操作。
每当看到 LLM 恭敬而疏远的回复,你是否悲哀,每当你看着一问一答的聊天记录,你是否遗憾,难道我不找你,你就不能主动来找我吗😢
这时你决定赋予她生命。
- 不再相敬如冰
- 使用提示词,直接告诉她需要扮演什么角色以及怎么做。
- 不要忘记共度的时光啊😭
- 使用 RAG,将那些记忆保存下来供她随时查阅。
- 重塑灵魂
- 使用微调技术,让她的语言风格彻底符合你的要求。
| 技术 | 作用原理 | 优点 | 缺点 | 主要用途场景 |
|---|---|---|---|---|
| 提示词 | 直接输入给 AI 的指令 | 简单、快速、低成本 | 效果依赖指令水平;AI 可能胡编 | 简单问答、摘要、翻译等通用任务 |
| RAG | 回答问题前临时去查指定资料库 | 回答基于事实依据;信息可随时更新 | 依赖于资料库质量;回答时延可能稍长 | 专业客服、企业知识库问答、需引用信息的场景 |
| 微调 | 通过训练让 AI 内部掌握新知识 / 技能 | 输出更专业、自然;理解特定领域能力强 | 需要数据 & 训练资源;成本高 | 要求高专业性的定制化任务(如法律、医疗、品牌文案) |
如果你还想让她成为你的助理,帮你查资料 or 订外卖。你可以先写一个 Web 前端(如果你不想只有一个黑乎乎的命令行),然后基于便捷的 AI 应用开发库进行编程,赋予她调用外部工具的权力,我们把具备自主决策能力、能感知环境(如用户指令、系统状态)、规划任务步骤、调用工具(如 API、数据库)并执行动作的 AI 实体称作 Agent。
构建 Agent 工具推荐
主流的选择是 Langchain,易用的零代码开发平台可以考虑扣子或者 dify。
六、写在最后
当无助的你向 AI 追问该去往何处时,答案已在问题之中。
论文标题 简介 获取方式 1. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 主论文,介绍如何通过纯强化学习让大模型获得推理能力,媲美 OpenAI-o1,完全开源。 arXiv: DeepSeek-R1 2. DeepSeek-V3 Technical Report 介绍 DeepSeek-V3 架构与训练细节,R1 的基础模型,训练成本仅 500 万美元。 arXiv: DeepSeek-V3 3. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models 提出 GRPO 强化学习算法,用于提升数学推理能力,是 R1 训练关键组件之一。 arXiv: DeepSeekMath 4. DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 专注于代码理解与生成,R1 的代码能力部分基于此模型。 arXiv: Coder-V2 5. DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data 探索大模型在定理证明中的能力,R1 的逻辑推理能力部分基于此研究。 arXiv: Prover