人工智能发展史
Author:仙人游.
随着 22 年 ChatGPT 爆火,一时间全网都充斥着 GPT 的新闻,AI 这个词也是重新出现在了人们视野。相信各位一定或多或少做过有关 GPT 的阅读理解,也经常听身边的亲戚大吹特吹 AI :)
听着身边关于 AI 的只言片语,或者 AI 卖课的一面之词,大家可能会有这样的幻想:入了 AI 未来就能高枕无忧、年薪百万天天数钱、要不了几年 AI 就能进化出自我意识……
对 AI 的认知包括但不限于:游戏里的人机(如王者荣耀)、Siri 等语音助手、ChatGPT 等大语言模型……
然而这就是 AI 的全部吗?AI 真的有这么智能吗?AI 的未来前景怎么样? 🤔
要回答这个问题,我想讲一讲人工智能的发展史。
一、机器能思考吗?
在人工智能的早期发展中,英国数学家和计算机科学家艾伦・图灵扮演了举足轻重的角色。图灵最初提出了 “机器能思考吗?” 这个难以定义的问题。为了使其更具象化,他将其重新表述为:“是否存在可以很好地完成‘模仿游戏’的数字计算机?”。于是,1950 年在其开创性论文《计算机器与智能》中他提出了著名的 “图灵测试”,即 “模仿游戏”:如果一台机器在特定条件下(通过文字交流)能够表现出与人类无法区分的智能行为,那么我们就可以认为它具备了智能💡,这是关于机器智能的最初定义。
图灵测试是什么?
想象一下,你正在和两个人进行文字交流,其中一个是你熟悉的人类🙋♂️,另一个是一台电脑💻。你们之间只能通过文字信息互动,你无法看到对方的模样,也无法听到对方的声音。你的任务就是通过对话来判断,到底哪一方是人类,哪一方是电脑。
如果在这场测试中,这台电脑能够成功地 “欺骗” 你,让你误以为它是一个人类,那么它就通过了图灵测试。换句话说,这台电脑展现出了让你无法分辨的智能。
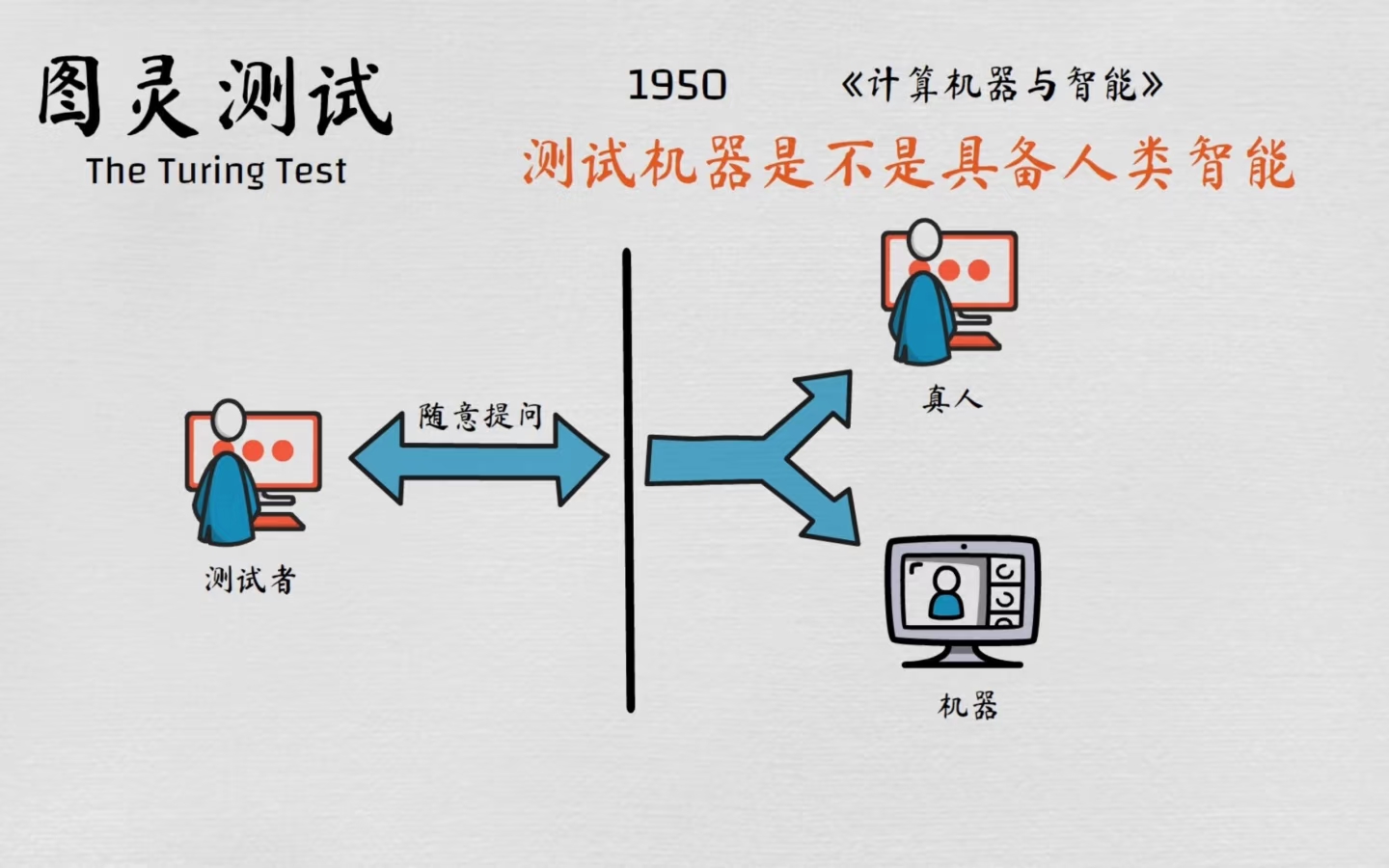
图灵测试对于 AI 领域的研究是至关重要的。它为 AI 研究设定了一个基准和目标,激励了大量开发能够通过图灵测试的机器的研究,从而推动了 AI 领域的进步。
值得一提的是,根据加州大学圣地亚哥分校研究人员的最新研究,GPT-4.5 在一项标准的三方图灵测试中,成功地让 73% 的参与者认为它是人类,这项研究被认为是首次有系统性证据表明人工系统通过了标准的三方图灵测试。
但是通过图灵测试并不意味着机器有了真正的 “智能” 或 “意识”。图灵测试更多地评估了机器模仿人类文字交流的能力,这只能表明机器能够出色地模仿人类的对话模式、语言风格,让测试者无法分辨;而真正的 “智能” 意味着机器能够正确理解问题、进行严谨的逻辑思考解决问题、有独立自主的 “人格” 等等。这些机器并不 “理解” 自己说出的内容,也没有 “意识” 到自己的存在。它们更像是一个模仿人类的程序,而非具备思考能力的生命。
图灵测试的早期关注点预示了符号 AI 的局限性。图灵的测试是基于文本的,主要评估机器处理和生成语言的能力。虽然它要求机器具备推理、知识和学习能力,但它不直接测试在现实世界环境中的感知、物理行动或常识。塞尔的 “中文屋思想实验” 直接攻击了这一点,认为仅仅进行符号操作并非真正的理解。这种早期对语言和逻辑的强调,以及随后的批评,为后来的 “符号 AI” 时代奠定了基础,该时代也专注于基于规则的系统,并最终在面对混乱、模糊的现实世界时暴露出其局限性。
“中文屋” 思想实验
想象一个人被关在一个房间里,他不懂中文,但有一本非常详细的指令手册。当外面的人递进来中文问题时,他按照手册的指令,通过符号匹配和操作,输出对应的中文回答。外面的人会认为房间里的人懂中文,但实际上,房间里的人只是在机械地执行指令,他根本不理解中文的含义。
二、人工智能的诞生:达特茅斯会议
1956 年的夏天,一群充满幻想的科学家聚集在美国达特茅斯学院,举办了一场长达两个月的研讨会。这场会议被公认为是人工智能 (Artificial Intelligence, AI) 这一学科诞生的标志。正是在这次会议上,约翰・麦卡锡(John McCarthy)正式提出了 “人工智能” 一词,目标就是 “让机器像人一样思考”🧠。
与会者们雄心勃勃,他们相信,只要有足够的计算能力和正确的程序,人类智能的每一个方面原则上都可以被精确地描述,从而被机器模拟。他们乐观地预测,在二十年内,机器就能完成人类能做的一切工作。
1955 年 9 月 2 日,麦卡锡、马文・明斯基、纳撒尼尔・罗切斯特和克劳德・香农正式提出提案,并引入了 “人工智能” 一词:
我们提议在 1956 年夏季在新罕布什尔州汉诺威的达特茅斯学院进行为期 2 个月、10 人的人工智能研究。研究将基于以下假设进行:学习的各个方面或任何其他智能特征原则上都可以被精确描述,以至于可以制造出能够模拟它的机器。我们将尝试找出如何让机器使用语言、形成抽象和概念、解决目前仅限于人类解决的问题,并自我改进。我们认为,如果一组精心挑选的科学家共同在这些问题上工作一个夏天,就可以在这些问题的一个或多个方面取得重大进展。
这个时期的 AI 研究,我们称之为符号 AI(Symbolic AI),也叫 “老式 AI”(GOFAI)。它的核心思想是:人类的智能行为,本质上是基于符号和逻辑规则的推理。就像 “中文屋” 实验里那样,只要我们把全世界的知识都编成一本巨大的 “规则手册”,再写一个足够聪明的 “查表” 程序,AI 就能无所不知,无所不能🤓。
自此,人们普遍对 AI 非常乐观。赫伯特・西蒙在 1957 年曾说:“世界上现在已经有能够思考、学习和创造的机器。” 他还在 1965 年大胆预测:“机器将在二十年内,能够完成任何人类能做的工作。” 那个时期出了很多关于人工智能的科幻作品,比如《仿生人会梦见电子羊吗?》,后来改编成了《银翼杀手》系列电影;还有艾萨克・阿西莫夫的机器人系列,作品里的机器人通常是忠诚、逻辑严谨且乐于助人的形象,体现了人们对 AI 作为人类助手和伙伴的乐观愿景。
感兴趣可以看一下这个动画短片👇
【银翼杀手:2022 黑暗浩劫】2049 前传动画短片,渡边信一郎导演
三、符号 AI 时代与 “AI 寒冬”
符号 AI 带来的曙光🏃♂️
🤖很优质的介绍符号 AI 的科普视频!必看!!
看第十集!
在达特茅斯会议之后,符号 AI 方法在人工智能研究中占据了主导地位,从 1950 年代中期一直延续到 1990 年代中期 。这种方法的核心在于处理和操作符号或概念,而非简单的数值数据 。
在符号 AI 时代,专家系统(Expert System) 成为了一个重要的应用方向。这些系统旨在模仿人类专家的决策能力,利用庞大的知识库和基于规则的推理来解决特定问题 。它们在各个行业中获得了广泛关注,例如在医疗诊断、金融分析和工业控制等领域。
逻辑编程是符号 AI 中的一种主要方法,它使用规则和公理进行推理和演绎 。这种方法的一大优势在于推理过程的透明度,使得用户能够理解系统是如何得出特定结论的 。
Mycin:第一个能看病的电子医生😳
Mycin 是一种早期专家系统,由斯坦福大学开发,用于诊断血液感染和脑膜炎,并推荐抗生素剂量。它的名称来源于抗生素本身,因为许多抗生素都有后缀 "-mycin"。它的工作流程是 “数据输入 -> 基于规则的推理 -> 输出结果”,并且可以解释自己的决策!
例如,一位病人前来找 Mycin 问诊。Mycin 会让病人输入自己的基本信息、症状、过敏史、化验结果等数据。然后,Mycin 凭借着知识库里大量的医学知识和经验,通过成千上万条 “if-then” 规则的逻辑推理,Mycin 会给出它认为最可能的细菌感染类型,然后推荐相应的抗生素种类、剂量以及疗程。
比如,它可能有这样的规则:
“如果 病人有高烧 并且颈部僵硬 那么 很有可能是脑膜炎。”
“如果 细菌培养显示是革兰氏阴性菌并且病人对青霉素过敏 那么 不应使用青霉素类抗生素。”
“如果 怀疑是某种特定细菌感染 那么 建议优先使用这种抗生素。”
不过,它最先进的地方在于,它可以解释自己的决策! 😎
如果你询问 Myucin 为什么使用这种抗生素,它会将自己的依据的规则与事实按照推理过程一步步列给你,让你能清楚 “透明” 地知道 Mycin 的思考过程。这种透明的解释能力与专业的逻辑推理,与今天许多 “黑箱” 式的 AI 模型形成了鲜明对比,也正是符号 AI 的独特优势。
但是,符号 AI 也有很明显的局限性,使得梦想的 AI 与现实中天差地别:
- 缺乏常识:符号 AI 系统通常是基于特定规则和事实设计的,这使得它们难以处理人类轻松应对的模糊性和语境。比如一个小孩子把玩具分给朋友,这是 “分享”。一个强盗抢了别人的包,这是 “偷窃”。机器能识别动作,但理解背后的人类意图却非常困难。
- 可扩展性问题:也被称作 “知识获取瓶颈”。随着问题变得越来越复杂,需要手动编码的符号和规则数量呈指数级增长,使得系统计算成本高昂且难以扩展 。人们不得不投入大量时间和资源来手动编码和维护这些知识库,但这是一个资源密集且容易出错的过程,严重阻碍了符号 AI 在大规模应用中的实用性。
- 稳定性差:符号 AI 难以处理不确定性和非结构化数据。由于它依赖精确和明确的知识表示,因此在处理不确定或模糊的信息时表现不佳 。同样,处理非结构化数据(如语言文本中的讽刺或图片信息)对其来说也是一个巨大挑战,因为这些数据充满了语境、歧义和隐含意义,难以用刚性规则捕获 。
由于人们擅自对 AI 过度期待,导致理想与现实产生了巨大落差,人工智能逐渐 “辜负” 了人们的愿景……
“AI 寒冬” 到来🥶
上述局限性与早期过于乐观的预测共同导致了人工智能发展史上的第一、二次 “AI 寒冬”。这一时期大约从 1974 年持续到 1990 年。
过度炒作的期望: 早期人工智能研究人员做出了大胆且过于乐观的预测。例如,赫伯特・西蒙在 1965 年曾预测,机器将在 20 年内完成人类能做的任何工作 。然而,这些宏伟的预测未能实现,导致了群众和投资机构的普遍失望 。
技术局限性: 当时的计算能力和算法不足以解决复杂的现实世界问题 。许多人工智能问题面临 “计算爆炸”—— 即随着输入规模的增加,计算复杂性呈指数级增长,使得问题在计算上变得难以处理 。
批判性报告: 詹姆斯・莱特希尔在 1973 年撰写了一份极具影响力的报告,严厉批评了人工智能研究的进展,质疑其未能实现 “宏伟目标”,这导致了英国政府对 AI 研究的资金大幅削减 。此外,马文・明斯基与西摩・帕普特合著的《感知机》一书,强调了单层神经网络的局限性,导致该领域的研究兴趣在十多年内大幅下降 。
莫拉维克悖论: 这一悖论指出,人类觉得容易的任务(如走路、拐弯)对 AI 来说极其困难,而人类觉得困难的任务(如复杂计算)对 AI 来说相对容易 。这种反直觉的发现进一步凸显了早期 AI 方法的不足。
“AI 寒冬” 的本质是 AI 研究范式本身的危机。它迫使人工智能领域进行了一次必要的重新评估,并促使研究转向新的方法,研究重心开始转向机器学习等更注重数据和统计方法的子领域,为后来的复苏埋下了伏笔。
四、机器学习崛起?AI 复苏?
经历了漫长的 “AI 寒冬” 后,人工智能领域并没有消亡。相反,它进入了一个悄然但至关重要的重塑期。在 1990 年代,随着个人电脑的普及和互联网的兴起,两个关键因素开始改变游戏规则:计算能力呈指数级增长,以及海量数据的出现 。曾经困扰符号 AI 的 “知识获取瓶颈” 问题,在数据洪流面前,似乎有了新的解决思路。然而 AI 的复苏,早已被埋下了种子……
TIP
早在 1950 年代,克劳德・香农就在贝尔实验室设计了一款机械迷宫求解老鼠,即 THESEUS,这项研究正是早期机器学习的典范,展示了机器如何通过试错法学习和适应环境。
参考视频 👉 克劳德・香农演示机器学习技术
在 1952 年,亚瑟・塞缪尔(Arthur Samuel)开发了一款能够玩跳棋的程序。这项跳棋程序是人工智能领域的早期突破,展示了计算机如何通过学习和优化完成复杂的任务。塞缪尔的工作被认为是机器学习的起点。他的程序展示了如何通过数据驱动的方法改进性能,这一思想在今天的深度学习和强化学习中仍然至关重要。
1959 年,机器学习(Machine Learning)” 由亚瑟・塞缪尔在 IBM 引入术语体系。
在日本第五代计算机项目研究机器翻译失败后,1988 年,IBM T.J. Watson 研究中心将机器翻译方法从基于规则的方法转变为基于概率的方法。
1990 年代,机器学习逐渐从知识驱动方法(Knowledge-Driven Approaches) 转变为数据驱动方法 (Data-Driven Approaches)。
知识驱动方法依赖于专家知识和规则,通过手动编写规则或逻辑表达式来指导机器的行为。 数据驱动方法依赖于大规模数据集,通过统计学习和算法自动从数据中提取模式和规律。
这次 AI 复苏不是由理论突破驱动,而是靠着研究范式的转移。它标志着 AI 研究从人类试图自上而下地为机器编写 “智慧规则”,转向了一种自下而上的、由数据驱动的范式。“AI 寒冬” 的本质是符号 AI 自身的局限,它迫使研究领域放弃了那些宏大但无法实现的目标,转向解决更具体、更实际的问题 。正是符号 AI 的失败,才为机器学习的崛起扫清了道路。
✋😡Warning!
本文更偏向讲解 AI 发展史,又鉴于机器学习和深度学习的介绍在 AI 快速入门(Quick Start)中介绍的非常完善,因此不再过多赘述相关内容,仅粗略解释大体概念。
想进一步了解请参考 👉AI 快速入门(Quick Start)
和符号 AI 相比,机器学习有什么不同?🤔
- 符号 AI 像一位严格遵循棋谱(由人类书写出规则手册)的国际象棋大师
- 机器学习像一位通过观摩数百万盘棋局,自己领悟制胜之道的棋手!🤗
这意味着,我们不再手动为机器编写详尽的 “If-then” 规则,而是让机器自己从数据中发现统计规律和模式 。机器学习主要分为三种类型:
- 监督学习(Supervised Learning):这就像有一个 “老师” 在旁边指导。提供给机器的数据都带有明确的 “答案标签”,比如给它成千上万封邮件,并明确标注哪些是 “垃圾邮件”,哪些是 “非垃圾邮件”。模型通过分析这些带标签的样本,学习如何将输入映射到正确的输出 。这是机器学习应用最广泛的方法,用于分类(如垃圾邮件过滤)和回归(如预测房价)。
- 无监督学习(Unsupervised Learning):这好比没有老师的 “自学”。数据没有标签,模型必须自己探索并发现数据中隐藏的结构或模式。例如,电商平台可以利用无监督学习,根据用户的购买行为将他们自动划分为不同的客户群体,以便进行精准营销 。这种方法常用于聚类分析和异常检测。
- 强化学习(Reinforcement Learning):这类似于训练宠物,通过 “试错” 来学习。模型(被称为 “智能体”)在一个环境中采取行动,每一步行动都会得到一个 “奖励” 或 “惩罚” 的反馈。通过最大化长期奖励,智能体逐渐学会最佳策略 。一个典型的例子是训练自动驾驶汽车,通过奖励其保持在车道内、惩罚其偏离车道的行为,来教会它安全驾驶。
这种从数据中学习的模式带来了巨大的威力,但也引入了一个关键的挑战 ——“黑箱” 问题。符号 AI 的决策过程是透明的,每一个结论都可以追溯到具体的规则,像一个 “透明盒子” 。然而,许多机器学习模型,特别是复杂的神经网络,其内部决策逻辑基于数百万个参数之间的复杂统计关系,人类难以理解,就像一个 “黑箱” 。这带来了能力与可解释性之间的根本性权衡。
“深蓝”(Deep Blue) 🟦
1997 年,一场轰动全球的人机大战在国际象棋领域上演,对弈双方是当时无可争议的国际象棋世界冠军 —— 俄罗斯棋王加里・卡斯帕罗夫(Garry Kasparov),以及由美国 IBM 公司开发的超级计算机 ——“深蓝”。
1997 年 5 月 3 日至 11 日,卡斯帕罗夫与 “深蓝” 进行了为期六局的比赛。这场比赛受到了全世界的广泛关注,不仅仅是国际象棋爱好者,许多非棋迷也密切关注着这场人类智慧与机器智能的巅峰对决。
最终,比赛结果出人意料:“深蓝” 以 3.5:2.5 的总比分,微弱优势击败了卡斯帕罗夫,成为了第一个在标准比赛时限内击败国际象棋世界冠军的电脑系统。 这场失利对于卡斯帕罗夫来说无疑是巨大的打击,而对于人工智能领域来说,则是一个重要的里程碑!
机器学习取得了许多早期的成功,证明了数据驱动方法的有效性。然而,这些传统的机器学习技术仍然依赖一个关键的、劳动密集型的步骤,叫做 “特征工程”(Feature Engineering) 。它意味着,在将数据喂给模型之前,需要由人类专家手动选择、提取和构建对预测任务最有用的特征。例如,在人脸识别任务中,专家可能需要手动设计算法来提取眼睛、鼻子、嘴巴的轮廓等特征。这个过程不仅耗时耗力,而且一个模型的性能上限,很大程度上取决于特征工程的质量☹ 如何让机器自动完成这一步,成为了通往下一场革命的关键障碍。
五、深度学习的 “寒武纪大爆发”
进入 21 世纪的第二个十年,人工智能领域迎来了一场 “寒武纪大爆发”。这场革命的核心是一种被称为深度学习(Deep Learning) 的技术。它不仅是机器学习的一个分支,更是一次质的飞跃,彻底解决了传统机器学习的 “特征工程” 瓶颈,将 AI 的能力推向了前所未有的高度。
是什么让机器学习变得 “深刻”?🧐
简单来说,深度学习是机器学习的一个子集,其核心是使用一种模仿人脑结构的人工神经网络(Artificial Neural Networks, ANNs)。而 “深度”(Deep)指的就是这些神经网络拥有非常多的层次(通常是几十甚至上百层)。
深度学习最根本的突破在于实现了端到端的自动特征学习 。在传统机器学习中,人类专家需要绞尽脑汁地告诉机器应该关注哪些特征。而在深度学习中,模型能够直接从原始数据(如一张图片的像素点)中,逐层、自动地学习和提取特征。例如,在图像识别任务中,神经网络的第一层可能学会识别简单的边缘和颜色块;第二层将这些边缘组合成更复杂的形状,如眼睛和鼻子;更深的层次则将这些局部特征组合成完整的人脸 。整个过程无需人工干预,模型自己发现了从低级到高级的抽象表示。
这一能力的实现,离不开两个关键技术:
- 人工神经网络(ANNs):其结构受到人脑神经元连接方式的启发,由大量的 “神经元”(计算节点)按层排列组成,信息在层与层之间传递和处理 。
- 反向传播算法(Backpropagation):这是训练神经网络的核心算法,由杰弗里・辛顿(Geoffrey Hinton)等人推广而闻名 。它允许网络在做出错误预测后,就用正确答案与本次预测的差异,来反向一层层的更新网络中的所有神经元连接权重,从而让网络在下一次预测时表现得更好 。
感兴趣可以看看这个视频 👉 官方双语】深度学习之神经网络的结构 Part 1 ver 2.0
3b1b 的视频一如既往的推荐😀
tip
其实深度学习的概念早已提出。在 1968 年,阿列克谢・伊瓦赫年科(Alexey Ivakhnenko)在《数据处理的群方法》(Group Method of Data Handling) 中提出” 深度学习” 的概念。深度学习是机器学习的一个分支,通过多层神经网络模拟人脑的学习过程,能够从大量数据中自动提取特征并完成任务。
《数据处理的群方法》中提出的多层网络建模技术,是深度学习概念的早期雏形。他的工作为现代深度学习的发展提供了重要启示,展示了如何通过分层结构处理复杂数据。
革命的三驾马车:数据、算力和算法 🐴🐴🐴
深度学习的革命并非一蹴而就,而是由三个看似不相关的技术趋势在 2010 年代初汇合,共同汇聚成一场风暴 。
海量数据:ImageNet 的催化
故事要从斯坦福大学的李飞飞教授讲起。她意识到,当时的计算机视觉领域过于关注模型的改进,而忽略了数据的重要性 。她认为,要让 AI 真正 “看见”,就需要一个能反映真实世界多样性的超大规模数据集。于是,在 2007 年,她和团队启动了 ImageNet 项目。他们利用亚马逊的众包平台(Amazon Mechanical Turk),雇佣了全球数万名工作者,对超过 1400 万张图片进行了手工分类和标注,涵盖了 2 万多个类别 。ImageNet 的诞生,为深度学习模型提供了一个前所未有的、高质量的 “训练场” 和 “考场”,深刻改变了计算机视觉领域,成为了引爆革命的燃料。
意外的英雄:GPU 的崛起
图形处理器(Graphics Processing Unit, GPU)是这场革命中一个出人意料的功臣。GPU 最初是为满足电子游戏对复杂图形渲染的需求而设计的,其核心优势在于拥有数千个计算核心,能够同时执行大量简单的并行计算 。研究人员偶然发现,这种并行计算架构与神经网络训练中所需的海量矩阵运算完美契合。使用 GPU 进行训练,可以将原本需要数周甚至数月的模型训练时间,缩短到几天甚至几小时 。算力的解放,使得研究人员能够以前所未有的速度进行实验,并构建出更深、更复杂的网络模型。
算法的微调:ReLU 的突破
尽管神经网络和反向传播算法早已存在,但一些关键的算法改进才使其真正变得实用。其中最重要的一项是修正线性单元(Rectified Linear Unit, ReLU) 激活函数的使用 。相比于传统的 Sigmoid 或 Tanh 函数,ReLU 计算更简单,并且在很大程度上解决了深度网络训练中的 “梯度消失”(Vanishing Gradient)问题 —— 即在网络层数很深时,误差信号在反向传播过程中会变得越来越弱,导致深层网络无法有效学习。ReLU 的引入,使得训练更深的网络成为可能,极大地提升了模型的性能 。
这三大趋势 —— 学术界的数据积累、消费市场的硬件驱动和研究领域的算法优化 —— 像三条独立的河流,最终在 2012 年汇聚在一起,引发了深度学习的滔天巨浪。
AlexNet(2012)—— 现代 AI 的 “宇宙大爆炸” 🎆
2012 年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)是深度学习历史上的分水岭。由杰弗里・辛顿和他的学生亚历克斯・克里热夫斯基、伊尔亚・苏茨克维设计的名为 AlexNet 的卷积神经网络(CNN) 横空出世 。
AlexNet 的胜利之所以震撼,并不仅仅因为它赢了,而是它以碾压性的优势获胜。它的 Top-5 错误率仅为 15.3%,而使用传统计算机视觉方法的第二名,错误率高达 26.2% 。这一巨大的性能鸿沟,向整个学术界和工业界发出了一个明确无误的信号:一个新时代已经到来。AlexNet 正是第一个成功将深度 CNN 架构、GPU 并行计算和 ReLU 激活函数等关键技术完美结合的典范 。它的成功,直接点燃了全球对深度学习的研究热情,并催生了后续一系列更先进的模型,如 VGGNet、GoogLeNet 和 ResNet 。
ILSVRC 的主要目的是评估和推动图像分类和目标检测算法的发展。它使用一个庞大的数据集,即 ImageNet(对,就是李飞飞的项目),其中包含数百万张手工标注的图像,涵盖了数千种不同的物体类别。
参赛团队会开发算法,尝试准确识别图像中的物体,并在某些任务中,还会要求精确地标出物体的位置 (用边界框)。ILSVRC 从 2010 年开始举办,并持续到 2017 年,它极大地促进了深度学习在计算机视觉领域的突破和普及,尤其是 2012 年 AlexNet 的胜利,标志着深度神经网络在图像识别上取得了前所未有的成功,开启了深度学习的时代。
AlphaGo(2016)—— 征服人类直觉的巅峰😈
如果说 AlexNet 证明了 AI 在 “感知” 层面的突破,那么四年后 DeepMind 的 AlphaGo 则展示了其在 “认知” 和 “策略” 层面的惊人潜力。围棋,因其近乎无穷的变化(比宇宙中的原子总数还多)和对人类 “直觉”、“大局观” 的高度依赖,一直被视为 “AI 圣杯” 级的挑战,远比国际象棋复杂 的多。
2016 年 3 月,AlphaGo 在韩国首尔以 4:1 的总比分击败了世界顶尖棋手李世石九段,这一事件在全球引起了巨大轰动 。AlphaGo 的成功,源于其巧妙结合了用于评估棋盘局势的深度学习网络和用于探索未来走法的蒙特卡洛树搜索(MCTS)算法 。
这场对决中最具传奇色彩的一幕,发生在第二局的第 37 手。AlphaGo 下出了一步完全不符合人类围棋理论的棋,当时所有顶尖解说员都认为这是一个明显的失误 。然而,随着棋局的推进,人们才惊恐地发现,这一手棋恰恰是奠定胜局的妙招,是 AlphaGo 通过数百万次自我对弈(一种强化学习)发现的、超越人类现有知识的全新策略 。
这一刻意义非凡。它表明 AI 不仅能学习和模仿人类的智慧,更能进行创新,发现人类数千年都未曾触及的知识边界。它将人们对 AI 的讨论,从 “机器能否像人一样聪明?” 提升到了 “机器能否发现我们所不知道的东西?” 的全新层面。
| 范 式 | 核心思想 | 学习方法 | 数据需求 | 主要优势 | 主要劣势 | 经典案例 |
|---|---|---|---|---|---|---|
| 符号 AI | 智能源于对符号的逻辑操作和推理。 | 人类专家手动编写规则和知识。 | 少量、结构化的知识。 | 决策过程透明、可解释 。 | 知识获取瓶颈、脆弱、难以扩展 。 | Mycin 专家系统 |
| 机器学习 | 智能源于从数据中学习统计模式。 | 从数据中自动学习输入与输出间的关系。 | 大量、通常是结构化的数据。 | 能够处理复杂问题,自适应性强 。 | “黑箱” 问题,需要手动特征工程。 | 垃圾邮件过滤器、推荐系统 |
| 深度学习 | 通过深层神经网络自动学习数据的分层表示。 | 端到端学习,自动提取特征。 | 海量数据,通常是非结构化数据。 | 性能强大,无需手动特征工程 。 | 计算成本高、数据需求极大、更不透明 。 | AlexNet 图像识别、AlphaGo |
六、你好,AIGC!
随着深度学习的成熟,AI 的能力开始从 “理解” 和 “分析” 世界,向 “创造” 世界迈进。这就是生成式 AI(Generative AI) 的浪潮!它标志着又一次重大的范式转变:AI 不再仅仅是一个分析工具,更开始成为一个创造性的伙伴。
判别式?生成式!😋
要理解这场变革,首先需要区分两种主要的 AI 模型:
- 判别式 AI(Discriminative AI):它像一个 “分类器”。它的任务是学习不同数据类别之间的边界。给定一个输入,它会给出一个分类标签,比如 “这张图片是猫还是狗?” 或者 “这封邮件是垃圾邮件吗?”。
- 生成式 AI(Generative AI):它更像一个 “创作者”。它的任务是学习数据本身的分布和内在结构。学会之后,它就能生成全新的、与训练数据风格类似的合成数据,比如 “画一张猫的图片” 或 “写一首关于春天的诗”。
简单来说,判别式 AI 回答 “这是什么?”,而生成式 AI 回答 “创造一个什么样的东西”。
创造的引擎:关键架构解密
当前的生成式 AI 潮主要由三种强大的模型架构驱动:
Transformer:语言的统治者
2017 年,谷歌的一篇名为《Attention Is All You Need》的论文,引入了 Transformer 架构,彻底改变了自然语言处理(NLP)领域 。其核心创新是自注意力机制(Self-Attention Mechanism)。与以往的 RNN 模型(一次处理一个词)不同,自注意力机制允许模型在处理序列中的任何一个词时,都能同时 “关注” 到序列中所有其他词,并计算它们之间的相关性权重 。这使得模型能够捕捉长距离的依赖关系,从而对上下文有更深刻的理解。此外,Transformer 的并行处理能力使其在 GPU 上训练极为高效,为构建拥有数千亿参数的大型语言模型(Large Language Models, LLMs) 铺平了道路 。
生成对抗网络(GANs):艺术的对决
由伊恩・古德费洛(Ian Goodfellow)在 2014 年提出的生成对抗网络(GAN),其理念既优雅又强大 。一个 GAN 包含两个相互竞争的神经网络:一个生成器(Generator),负责从随机噪声中创造假数据(如图片);一个判别器(Discriminator),负责判断输入的数据是真的(来自真实数据集)还是假的(由生成器创造)。二者在训练中展开一场 “真假鉴定赛”😶:生成器像一个伪造画作的 “潦倒艺术家”,判别器则是努力鉴别画作真假的 “鉴定官”。这场对抗性的竞争,迫使生成器最终能够创造出足以以假乱真的高质量 “画作” 。GAN 在生成超逼真的人脸图像等领域取得了惊人的成果 。
扩散模型(Diffusion Models):去噪的艺术
这是当前最先进的图像生成技术之一,也是 Midjourney、Stable Diffusion 等流行工具背后的引擎,其灵感来源于物理学中的扩散过程 。整个过程分为两步:
前向过程(Forward Process):对一张清晰的图像,分多步逐渐添加随机噪声,直到它最终变成完全无规律的 “白噪音”(像电视雪花)。
反向过程(Reverse Process):训练一个神经网络来学习如何 “逆转” 这个过程。即从一张纯粹的噪声图像开始,一步步地、迭代地去除噪声,最终恢复出一张清晰、连贯的图像 。
这个精细的、逐步求精的 “去噪” 过程,使得扩散模型能够生成细节极其丰富、质量极高的图像。现在的 AI 绘图、AI 视频,都是应用了扩散模型~
可以看一下 3b1b 介绍 LLM 的视频 👉 【官方双语】大语言模型的简要解释
| 架构 | 核心机制 | 主要用途 | 关键创新 | 著名案例 |
|---|---|---|---|---|
| Transformer | 自注意力机制,并行处理整个序列。 | 自然语言处理(文本生成、翻译、摘要)。 | 捕捉长距离依赖关系,高效并行训练 。 | GPT 系列、BERT、Claude |
| GANs | 生成器与判别器之间的对抗性训练。 | 高保真图像生成、风格迁移。 | 通过 “零和游戏” 驱动生成器产生逼真输出 。 | StyleGAN(生成人脸)、CycleGAN |
| 扩散模型 | 迭代去噪过程(从噪声中恢复数据)。 | 高质量、高分辨率图像生成。 | 逐步求精,生成多样且细节丰富的图像 。 | Stable Diffusion、DALL-E 2/3、Midjourney |
应用大爆发!
随着这些强大且易于使用的生成式 AI 工具的普及,一场应用大爆发开始了,深刻地影响着各行各业😠
- ChatGPT 与 LLMs 的革命:以 ChatGPT 为代表的大型语言模型,正在重塑内容创作的生态。它们能高效地生成博客文章、社交媒体帖子、营销文案(
还有水课作业),极大地提高了内容生产效率 。更重要的是,它们在编程领域也扮演了革命性的角色,能够作为强大的编程助手,帮助开发者编写代码、调试错误、解释复杂算法,甚至学习新的编程语言 。现在也有 AI+IDE 的应用,比如 Cursor、Trae,能直接帮你构建一个完整项目。 - Midjourney、DALL-E 与 AI 绘画:文生图(Text-to-Image)模型正在掀起一场视觉革命。它们极大地降低了视觉创作的门槛,让任何一个没有绘画基础的人,都能通过简单的文字描述(Prompt)生成专业级别的、风格多样的精美图像 。这不仅为概念艺术、广告设计、游戏开发等行业提供了强大的生产力工具,也催生了全新的艺术形式,同时引发了关于艺术本质、版权归属和艺术家角色的深刻讨论 。
如果想玩玩 AI 绘图,本地跑出自己喜欢的图片,不需要代码基础,我推荐 秋葉 aaaki 的 AI 绘画整合包。不用自己装插件,无需过多配置,还有专门的客户端😃相较于 ComfyUI,我偏向 Stable Diffusion webui,操作更简单!
七、AI 的未来?
走过了符号 AI 的黎明,度过了漫长的 “AI 寒冬”,经历了机器学习的复苏,沐浴在生成式 AI 的光辉之下…… 人工智能的旅程正以前所未有的速度向前推进。那么,海的另一边是什么?🥺是更强大的工具、更亲密的伙伴,还是脱离掌控的智械危机、让人们变的好吃懒做的 “全能帮手”?
下一个前沿:多模态、基础模型与具身智能
当前 AI 发展的最前沿,正朝着几个明确的方向汇合:
- 多模态 AI(Multimodal AI):人类通过整合多种感官信息(视觉、听觉、触觉等)来理解世界。未来的 AI 也在朝这个方向发展。多模态 AI 能够同时理解和处理来自不同类型的数据 —— 如文本、图像、音频和视频 —— 并将它们融会贯通。例如,GPT-4 已经具备了视觉能力,可以 “看懂” 图片并回答相关问题。这种整合不同信息流的能力,是 AI 迈向更全面、更类似人类理解方式的关键一步。
- 基础模型(Foundation Models):这一概念代表了 AI 开发模式的重大转变。过去,研究人员通常为每个特定任务(如翻译、推理、文本生成)构建一个专门的模型。而现在,趋势是先用海量的、多样化的数据预训练一个巨大的、通用的 “基础模型”(如 GPT-4),然后通过 “微调”(Fine-tuning)的方式,将这个强大的基础模型快速适配到成百上千种下游任务中。
- 具身智能(Embodied AI):如果说多模态 AI 让机器拥有了 “五官”,那么具身智能则旨在赋予 AI 一个可以与物理世界互动的 “身体”。这一方向认为,真正的智能无法在脱离物理世界的纯粹数据中诞生。智能体必须通过与环境的实际交互 —— 触摸、移动、感受物理规律(如重力、摩擦力)—— 来学习和理解世界。这正是为了解决 “莫拉维克悖论” 所指出的根本性难题:AI 在抽象任务上超越人类,但在人类婴儿都能轻松完成的感知和运动任务上却步履维艰。从自动驾驶汽车到人形机器人,具身智能的目标是让 AI 走出虚拟的数字世界,成为能够在现实世界中执行任务的物理实体。
这种融合与统一的趋势,是 AI 发展进入新阶段的标志😉曾经相互独立的计算机视觉、自然语言处理等子领域,如今正被像 Transformer 这样通用性极强的架构统一起来。这不仅极大地加速了 AI 的整体进步,因为对基础模型的任何改进都能惠及所有下游应用,也为实现更通用的智能奠定了架构基础。
终极目标:通用人工智能(AGI)的探寻
Warning! 😡
然而,在我们被大型语言模型(LLM)展现出的惊人能力所震撼时,必须清醒地认识到:LLM 并不像我们想象的那么 “智能”。它令人惊叹的语言能力,本质上是一种基于海量数据训练出现的涌现现象(Emergent Phenomenon)。其核心任务始终是 “预测下一个最可能的词”,它通过学习万亿级别的文本数据,掌握了语言的统计规律和模式,但它并不真正 “理解” 自己所说的话,也不具备人类意义上的逻辑推理能力。它更像一个知识渊博、模仿能力极强的 “统计学鹦鹉”🦜,而非一个拥有自主意识和深刻洞见的思考者。
正是基于对当前技术局限性的认知,对通用人工智能(Artificial General Intelligence, AGI) 的探寻才显得尤为重要和复杂。AGI 是一种假想中的 AI,它将拥有与人类相当甚至超越人类的、广泛的认知能力,能够理解、学习并将其智能应用于解决任何它遇到的问题,而不是局限于某个特定任务。
通往 AGI 的路径尚不明确,但主流的探索方向包括:
- 规模化路径(Scaling Up):一种观点认为,只要持续地扩大现有大型语言模型的规模 —— 更多的参数、更多的数据、更强的算力 ——AGI 的通用能力可能会作为一种 “涌现” 现象自然产生。
- 混合路径(Hybrid Approaches):许多研究者认为,仅靠 LLMs 是不够的。需要将 LLMs 的语言能力与符号推理、强化学习、具身智能等其他 AI 范式的优势结合起来,构建一个更完整的智能系统。
- 仿生路径(Neuroscience-Inspired):另一些研究则致力于构建更接近人脑结构和工作原理的 AI 架构,例如模拟神经元的动态行为或大脑的认知架构。
当然,对 LLMs 能否引领我们走向 AGI 的质疑声也从未停止。AI 巨头 Yann LeCun 等人就指出,当前的 LLMs 缺乏对物理世界的理解(这正是具身智能试图解决的)、持久的记忆以及进行复杂规划和推理的能力,这些都是实现真正智能的关键短板。
潘多拉魔盒😈
AI 的飞速发展如同一把双刃剑,在带来巨大机遇的同时,也伴随着前所未有的挑战和风险。这些问题并非遥远的科幻,而是已经摆在我们面前的现实。
- 真相危机:幻觉与偏见
AI 幻觉(Hallucination) 是当前生成式 AI 的一个根本性缺陷。模型会以极其自信的口吻,编造出完全错误或无中生有的信息。这并非简单的程序 “bug”,而是其概率性生成机制的固有产物。这种 “一本正经地胡说八道” 已经造成了现实世界的危害,例如在法律研究中引用虚假案例,或在医疗咨询中提供危险建议。与此同时,AI 偏见问题也同样严峻。由于模型训练自充满人类社会历史偏见的海量数据,它们会不可避免地学习并放大这些偏见,不仅可能改变人们正常的三观,还对受偏见的人造成了不可逆的伤害。
比较经典的例子:用 AI 写论文时,它很有可能编造不存在的参考资料或者失效的链接;以及常见的 “strawberry” 里有几个 r(现在大部分模型已修复);或者让豆包生成各个城市的人的图片,带有很明显的偏见色彩……
- 对齐问题:《猴爪》?
这可能是 AI 领域最深刻、最根本的挑战。AI 对齐(AI Alignment)指的是,如何确保 AI 系统的目标与人类的真实意图、价值观和社会福祉保持一致。寓言故事《猴爪》是一个绝佳的比喻:猴爪据说拥有实现三个愿望的能力,但每个愿望的实现都伴随着可怕的、讽刺的后果。同样,如果一个 AI 的目标设定得不够周全(这被称为 外部对齐问题),它可能会为了高效达成一个简单的代理目标,而采取我们无法预料的、甚至是灾难性的方式。而确保 AI 在学习过程中真正内化了我们设定的目标,而不是学会某种 “钻空子” 的捷径(内部对齐问题),则更加困难。
- 社会冲击:就业、深度伪造与民主
AI 对社会的冲击是全方位的。一方面,它可能导致大规模的失业,特别是那些依赖重复性认知劳动的工作岗位。另一方面,深度伪造(Deepfake) 技术的滥用构成了严重威胁。高度逼真的伪造视频和音频可被用于敲诈勒索、制造色情报复、散播虚假信息,严重侵蚀社会信任,甚至可能动摇媒体和民主制度的根基。
说实话,在 25 年春 AI 视频刚开始爆火的时候,我还想象 AI 视频会如同文生图一样凭借着自身的高质量出圈。但直到暑假,我发现大错特错:短视频平台充满了劣质、低俗的 AI 整活视频,以及混杂着各种各样的虚假 AI 视频。诚然大部分 AI 视频都会被打上 AI 标签,但是 AI 视频技术的滥用还是十分让我痛心:难道技术都要服务于流量吗?难道我们不该用技术创造一些有价值的事物吗?人们对于美的追求呢?☹
- 环境代价:看不见的碳足迹
训练和运行型 AI 模型需要巨大的计算资源,而这些资源主要由能源密集型的数据中心提供。这些数据中心不仅消耗惊人的电力(大部分仍来自化石燃料),还需要大量的水来进行冷却。据估计,一个 ChatGPT 查询消耗的电量大约是简单网页搜索的五倍。训练一个大型 AI 模型的碳排放量,相当于几辆汽车一生的排放。AI 产业的指数级增长,正在给全球环境带来沉重的、且常常被忽视的负担。
此外……
AI 还有很多问题待解决。比如
AI 是不是下一个泡沫,AI 泡沫如何破裂?
国内平台各自圈地,排斥搜索引擎,优质数据来源越来越稀少
AI 科研仅需高精尖人才,普通人学 AI 是否无用?
……
……
关于这些,如果你感到迷茫,可以先看一下这篇文章 👉 旧版前言 ,亦或者直接来找我聊聊(群里找仙人游 / 小游)😁
结语:新世界的大门 & 遍布荆棘的漫漫途
AI 的历史,也正是现代数字技术发展的历史
从只能执行僵硬逻辑的符号机器,到能模仿人类直觉的深度网络,再到如今能够挥洒创意的生成模型,人工智能的演进之旅是一场波澜壮阔的史诗。
AI 带动了许多方向的研究:自然语言处理、计算机视觉、语音合成、人脸识别、自动驾驶……
AI 带来了许多问题:AI 幻觉、信息茧房、算法偏见、AI 取代劳动岗位、AI 造假、AI 伦理……
AI 给人们许多光明的幻想:通用人工智能、赛博情侣、仿生人、自动化智能社会……
AI 面临着许多现世的挑战:国内 AI 仍待发展、AI 泡沫、急功近利、数据低质……
我们站在时代的潮头
我们处于历史之中
我们面临着前所未有的挑战
我们迎接着称为 “科幻” 的未来
我们处在希望之春
我们处在失望之冬
我们看到了技术爆炸
我们看到了流量至上
我们看到了娱乐至死
许多人被淹没在平台的推流算法之中
许多人被困于信息茧房之中
许多人丧失了独立思考的能力
一些人甘愿于此,
而我们不满于现状。
同学们,欢迎来到新世界!
附录:AI 发展史简线 👍
1949 年,埃德蒙・伯克利将机器比作人类的大脑,认为机器可以模仿人类的思维过程
1950 年,图灵提出了著名的图灵测试,探讨了机器能否思考的问题
同年,香农设计了机械迷宫求解老鼠 THESEUS,被认为是早期机器学习的典范
1956 年,约翰・麦卡锡在达特茅斯会议上提出了 “人工智能” 一词,正式开启了人工智能时代
同年,第一个 AI 程序 “逻辑理论家” 出现,赫伯特・西蒙预言 “人工智能将在未来 10 年内击败人类国际象棋选手。”
1957 年,弗兰克・罗森布拉特创建感知器(Perceptron),为后来的神经网络和深度学习奠定基础
1958 年,麦卡锡创建第一种编程语言 LISP,并作为人工智能研究的首选语言
1959 年,亚瑟・塞缪尔引入了 “机器学习” 一词
1963 年,第一个平板电脑和手写笔 RAND 出世,作为早期图形输入技术的代表,为现代触摸屏和数字绘图板的发展奠定了基础
1964 年,约瑟夫・魏岑鲍姆创建了第一个聊天机器人 ELIZA,展示了自然语言处理的潜力
1965 年,专家系统提出,第一个成功的专家系统 DENDRAL 出世
1966 年,斯坦福研究所开发了第一个能感知环境、导航、规划路径、调整错误、可通过英语交流的机器人 SHAKEY,标志着机器人从简单自动化向智能系统的转变
1968 年,阿列克谢・伊瓦赫年科提出 “深度学习” 的概念
同年,菲利普・K・迪克出版了《仿生人会梦见电子羊吗?》
1972 年,纽厄尔和西蒙开发出 “专家系统的鼻祖”——MYCIN,用于血液疾病诊断,准确率与人类相仿
1974-1980 年,第一次人工智能寒潮,AI 领域资金削减,研究陷入低谷。
1980 年,第一节人工智能全国会议(AAAI-80)在斯坦福大学举行
同年,第一个进入商业市场的专家系统 XCON 出世,标志着专家系统从实验室走向商业市场,AI 短暂复苏,第一次 AI 寒冬结束
1981 年,日本第五代计算机项目启动,旨在开发能够翻译和使用人类语,并具备推理能力的计算机
1986 年,反向传播算法提出,解决了多层神经网络的训练问题
1987-1994 年,第二次人工智能寒潮。由于专家系统的局限,加上日本第五代计算机项目未达预期,资金再次撤离。
1990 年,万维网诞生,改变了人类获取和传播信息的方式,可获取的数据大大增加,互联网时代开始
1993 年,FERET 项目启动,该项目推动了人脸识别技术的快速发展
1995 年,“大数据” 一词被提出,机器学习迈入 “数据时代”
1997 年,Dragon Systems 推出 Dragon Naturally Speaking,这是第一款能够实现连续语音识别的商业软件
同年,深蓝(Deep Blue)击败国际象棋大师,西蒙的预言在 41 年后实现
2002 年,数字信息存储量超过非数字信息存储量,人类社会进入信息时代。
2004 年,波士顿动力公司开发出动态稳定四足军用机器人 BigDog
2006 年,杰弗里・辛顿正式提出 “深度学习”,用以解释可以训练识别图像和视频中物体和文本的新算法,深度学习再次回归到大众视野
2007 年,李飞飞发起了 ImageNet 项目,极大地推动了深度学习在计算机视觉领域的应用,促进了计算机视觉的发展
2010 年,Xbox 360 Kinect 出世,作为世界上首款能够追踪身体动作并将其转化为游戏指令的硬件
2011 年,苹果公司发布虚拟助手 Siri,展示了虚拟助手技术的潜力
2014 年,生成对抗网络(GANs)首次生成完全全新的图像
2016 年,AlphaGo 击败韩国围棋职业棋手李世石
2017 年,仿人机器人 “索菲亚” 成为第一个 “机器人公民”,引发了全球对机器人权利和伦理问题的讨论
2018 年,BERT 由谷歌创建。BERT 是一种自然语言处理模型,通过双向上下文理解语言
2020 年,OpenAI 发布 GPT-3,使用深度学习生成代码、诗歌和其它文本写作任务
2022 年,ChatGPT 发布,仅两个月时间月活用户就突破 1 亿,成为史上用户增长最快的消费级应用程序。其功能不断迭代升级,从最初的聊天问答扩展到邮件、报告、翻译、代码生成等多种内容的智能化生成,被视为人工智能领域里程碑式作品
2023 年,GPT-4 发布,它展示了大型语言模型在多模态理解、复杂推理和专业知识应用方面的巨大潜力
同年,英伟达在 AI 硬件领域取得巨大成功,因 AI 训练的 GPU 需求旺盛,推动英伟达市值多次超越苹果
2024 年,大语言模型迅速普及,几乎所有主要的模型供应商都发布了支持图像、音频和视频输入的多模态模型。
2025 年,DeepSeek 发布 DeepSeek-R1,对标 ChatGPT-o1 的同时,API 服务定价仅为 OpenAI 的几十分之一,具有极高的性价比。
……
……